In C++, there are four types of casting operators.
static_cast
const_cast
reinterpret_cast
dynamic_cast
In this article we will only be looking into the first three casting operators as dynamic_cast is very different and is almost exclusively used for handling polymorphism only which we will not be addressing in this article.
static_cast
Format:
static_cast<type>(expression);
1
float fVariable = static_cast<float>(iVariable); /*This statement converts iVariable which is of type int to float. */
By glancing at the line of code above, you will immediately determine the purpose of the cast as it is very explicit. The static_cast tells the compiler to attempt to convert between two different data types. It will convert between built-in types, even when there is a loss of precision. In addition, the static_cast operator can also convert between related pointer types.
1 2 3
int* pToInt = &iVariable; float* pToFloat = &fVariable; float* pResult = static_cast<float*>(pToInt); //Will not work as the pointers are not related (they are of different types).
const_cast
Format:
1
const_cast<type>(expression);
1 2 3 4 5 6 7 8 9 10 11 12 13 14
voidaFunction(int* a) { cout << *a << endl; }
intmain() { int a = 10; constint* iVariable = &a;
aFunction(const_cast<int*>(iVariable));
return0; }
Probably one of the most least used cast, the const_cast does not cast between different types. Instead it changes the “const-ness” of the expression. It can make something const what was not const before, or it can make something volatile/changeable by getting rid of the const. Generally speaking, you will not want to utilise this particular cast in your programs. If you find yourself using this cast, you should stop and rethink your design.
reinterpret_cast
Format:
1
reinterpret_cast<type>(expression);
Arguably one of the most powerful cast, the reinterpret_cast can convert from any built-in type to any other, and from any pointer type to another pointer type. However, it cannot strip a variable’s const-ness or volatile-ness. It can however convert between built in data types and pointers without any regard to type safety or const-ness. This particular cast operator should be used only when absolutely necessary.
Modern Cocoa development involves a lot of asynchronous programming using closures and completion handlers, but these APIs are hard to use. This gets particularly problematic when many asynchronous operations are used, error handling is required, or control flow between asynchronous calls gets complicated. This proposal describes a language extension to make this a lot more natural and less error prone.
This paper introduces a first class Coroutine model to Swift. Functions can opt into to being async, allowing the programmer to compose complex logic involving asynchronous operations, leaving the compiler in charge of producing the necessary closures and state machines to implement that logic.
It is important to understand that this is proposing compiler support that is completely concurrency runtime-agnostic. This proposal does not include a new runtime model (like “actors”) - it works just as well with GCD as with pthreads or another API. Furthermore, unlike designs in other languages, it is independent of specific coordination mechanisms, such as futures or channels, allowing these to be built as library feature. The only runtime support required is compiler support logic for transforming and manipulating the implicitly generated closures.
This draws some inspiration from an earlier proposal written by Oleg Andreev, available here. It has been significantly rewritten by Chris Lattner and Joe Groff.
Motivation: Completion handlers are suboptimal
To provide motivation for why it is important to do something here, lets look at some of the problems that Cocoa (and server/cloud) programmers frequently face.
Problem 1: Pyramid of doom
Sequence of simple operations is unnaturally composed in the nested blocks. Here is a made up example showing this:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
funcprocessImageData1(completionBlock: (result: Image) -> Void) { loadWebResource("dataprofile.txt") { dataResource in loadWebResource("imagedata.dat") { imageResource in decodeImage(dataResource, imageResource) { imageTmp in dewarpAndCleanupImage(imageTmp) { imageResult in completionBlock(imageResult) } } } } }
processImageData1 { image in display(image) }
This “pyramid of doom” makes it difficult to keep track of code that is running, and the stack of closures leads to many second order effects.
Problem 2: Error handling
Handling errors becomes difficult and very verbose. Swift 2 introduced an error handling model for synchronous code, but callback-based interfaces do not derive any benefit from it:
Problem 3: Conditional execution is hard and error-prone
Conditionally executing an asynchronous function is a huge pain. Perhaps the best approach is to write half of the code in a helper “continuation” closure that is conditionally executed, like this:
1 2 3 4 5 6 7 8 9 10 11 12
funcprocessImageData3(recipient: Person, completionBlock: (result: Image) -> Void) { let continuation: (contents: image) -> Void = { // ... continue and call completionBlock eventually } if recipient.hasProfilePicture { continuation(recipient.profilePicture) } else { decodeImage { image in continuation(image) } } }
Problem 4: Many mistakes are easy to make
It’s easy to bail out by simply returning without calling the appropriate block. When forgotten, the issue is very hard to debug:
1 2 3 4 5 6 7 8 9 10 11 12 13
funcprocessImageData4(completionBlock: (result: Image?, error: Error?) -> Void) { loadWebResource("dataprofile.txt") { dataResource, error in guardlet dataResource = dataResource else { return// <- forgot to call the block } loadWebResource("imagedata.dat") { imageResource, error in guardlet imageResource = imageResource else { return// <- forgot to call the block } ... } } }
When you do not forget to call the block, you can still forget to return after that. Thankfully guard syntax protects against that to some degree, but it’s not always relevant.
1 2 3 4 5 6 7 8
funcprocessImageData5(recipient:Person, completionBlock: (result: Image?, error: Error?) -> Void) { if recipient.hasProfilePicture { iflet image = recipient.profilePicture { completionBlock(image) // <- forgot to return after calling the block } } ... }
Problem 5: Because completion handlers are awkward, too many APIs are defined synchronously
This is hard to quantify, but the authors believe that the awkwardness of defining and using asynchronous APIs (using completion handlers) has led to many APIs being defined with apparently synchronous behavior, even when they can block. This can lead to problematic performance and responsiveness problems in UI applications - e.g. spinning cursor. It can also lead to the definition of APIs that cannot be used when asynchrony is critical to achieve scale, e.g. on the server.
Problem 6: Other “resumable” computations are awkward to define
The problems described above are on specific case of a general class of problems involving “resumable” computations. For example, if you want to write code that produces a list of squares of numbers, you might write something like this:
1 2 3
for i in1...10 { print(i*i) }
However, if you want to write this as a Swift sequence, you have to define this as something that incrementally produces values. There are multiple ways to do this (e.g. using AnyIterator, or the sequence(state:,next:) functions), but none of them approach the clarity and obviousness of the imperative form.
In contrast, languages that have generators allow you to write something more close to this:
1 2 3 4 5 6 7 8
funcgetSequence() -> AnySequence<Int> { let seq = sequence { for i in1...10 { yield(i*i) } } returnAnySequence(seq) }
It is the responsibility of the compiler to transform the function into a form that incrementally produces values, by producing a state machine.
Proposed Solution: Coroutines
These problem have been faced in many systems and many languages, and the abstraction of coroutines is a standard way to address them. Without delving too much into theory, coroutines are an extension of basic functions that allow a function to return a value or be suspended. They can be used to implement generators, asynchronous models, and other capabilities - there is a large body of work on the theory, implementation, and optimization of them.
This proposal adds general coroutine support to Swift, biasing the nomenclature and terminology towards the most common use-case: defining and using asynchronous APIs, eliminating many of the problems working with completion handlers. The choice of terminology (async vs yields) is a bikeshed topic which needs to be addressed, but isn’t pertinent to the core semantics of the model. See Alternate Syntax Options at the end for an exploration of syntactic options in this space.
It is important to understand up-front, that the proposed coroutine model does not interface with any particular concurrency primitives on the system: you can think of it as syntactic sugar for completion handlers. This means that the introduction of coroutines would not change the queues that completion handlers are called on, as happens in some other systems.
Async semantics
Today, function types can be normal or throwing. This proposal extends them to also be allowed to be async. These are all valid function types:
1 2 3 4
(Int) -> Int// #1: Normal function (Int) throws -> Int// #2: Throwing function (Int) async -> Int// #3: Asynchronous function (Int) async throws -> Int// #4: Asynchronous function, can also throw.
Just as a normal function (#1) will implicitly convert to a throwing function (#2), an async function (#3) implicitly converts to a throwing async function (#4).
On the function declaration side of the things, you can declare a function as being asynchronous just as you declare it to be throwing, but use the async keyword:
1 2 3 4
funcprocessImageData() async -> Image { ... }
// Semantically similar to this: funcprocessImageData(completionHandler: (result: Image) -> Void) { ... }
Calls to async functions can implicitly suspend the current coroutine. To make this apparent to maintainers of code, you are required to “mark” expressions that call async functions with the new await keyword (exactly analogously to how try is used to mark subexpressions that contain throwing calls). Putting these pieces together, the first example (from the pyramid of doom explanation, above) can be rewritten in a more natural way:
funcprocessImageData1() async -> Image { let dataResource = await loadWebResource("dataprofile.txt") let imageResource = await loadWebResource("imagedata.dat") let imageTmp = await decodeImage(dataResource, imageResource) let imageResult = await dewarpAndCleanupImage(imageTmp) return imageResult }
Under the hood, the compiler rewrites this code using nested closures like in example processImageData1 above. Note that every operation starts only after the previous one has completed, but each call site to an async function could suspend execution of the current function.
Finally, you are only allowed to invoke an async function from within another async function or closure. This follows the model of Swift 2 error handling, where you cannot call a throwing function unless you’re in a throwing function or inside of a do/catch block.
Entering and leaving async code
In the common case, async code ought to be invoking other async code that has been dispatched by the framework the app is built on top of, but at some point, an async process needs to spawn from a controlling synchronous context, and the async process needs to be able to suspend itself and allow its continuation to be scheduled by the controlling context. We need a couple of primitives to enable entering and suspending an async context:
// NB: Names subject to bikeshedding. These are low-level primitives that most // users should not need to interact with directly, so namespacing them // and/or giving them verbose names unlikely to collide or pollute code // completion (and possibly not even exposing them outside the stdlib to begin // with) would be a good idea.
/// Begins an asynchronous coroutine, transferring control to `body` until it /// either suspends itself for the first time with `suspendAsync` or completes, /// at which point `beginAsync` returns. If the async process completes by /// throwing an error before suspending itself, `beginAsync` rethrows the error. funcbeginAsync(_ body: () async throws -> Void) rethrows -> Void
/// Suspends the current asynchronous task and invokes `body` with the task's /// continuation closure. Invoking `continuation` will resume the coroutine /// by having `suspendAsync` return the value passed into the continuation. /// It is a fatal error for `continuation` to be invoked more than once. funcsuspendAsync<T>( _ body: (_ continuation: @escaping (T) -> ()) -> () ) async -> T
/// Suspends the current asynchronous task and invokes `body` with the task's /// continuation and failure closures. Invoking `continuation` will resume the /// coroutine by having `suspendAsync` return the value passed into the /// continuation. Invoking `error` will resume the coroutine by having /// `suspendAsync` throw the error passed into it. Only one of /// `continuation` and `error` may be called; it is a fatal error if both are /// called, or if either is called more than once. funcsuspendAsync<T>( _ body: (_ continuation: @escaping (T) -> (), _ error: @escaping (Error) -> ()) -> () ) async throws -> T
These are similar to the “shift” and “reset” primitives of delimited continuations. These enable a non-async function to call an async function. For example, consider this @IBAction written with completion handlers:
This is an essential pattern, but is itself sort of odd: an async operation is being fired off immediately (#1), then runs the subsequent code (#3), and the completion handler (#2) runs at some time later — on some queue (often the main one). This pattern frequently leads to mutation of global state (as in this example) or to making assumptions about which queue the completion handler is run on. Despite these problems, it is essential that the model encompasses this pattern, because it is a practical necessity in Cocoa development. With this proposal, it would look like this:
extensionDispatchQueue{ /// Move execution of the current coroutine synchronously onto this queue. funcsyncCoroutine() async -> Void { await suspendAsync { continuation in sync { continuation } } }
/// Enqueue execution of the remainder of the current coroutine /// asynchronously onto this queue. funcasyncCoroutine() async -> Void { await suspendAsync { continuation in async { continuation } } } }
Generalized abstractions for coordinating coroutines can also be built. The simplest of these is a future, a value that represents a future value which may not be resolved yet. The exact design for a Future type is out of scope for this proposal (it should be its own follow-on proposal), but an example proof of concept could look like this:
// Fulfill the future, and resume any coroutines waiting for the value. funcfulfill(_ value: T) { precondition(self.result == nil, "can only be fulfilled once") let result = .value(value) self.result = result for awaiter in awaiters { // A robust future implementation should probably resume awaiters // concurrently into user-controllable contexts. For simplicity this // proof-of-concept simply resumes them all serially in the current // context. awaiter(result) } awaiters = [] }
// Mark the future as having failed to produce a result. funcfail(_ error: Error) { precondition(self.result == nil, "can only be fulfilled once") let result = .error(error) self.result = result for awaiter in awaiters { awaiter(result) } awaiters = [] }
funcget() async throws -> T { switch result { // Throw/return the result immediately if available. case .error(let e)?: throw e case .value(let v)?: return v // Wait for the future if no result has been fulfilled. casenil: return await suspendAsync { continuation, error in awaiters.append({ switch $0 { case .error(let e): error(e) case .value(let v): continuation(v) } }) } } }
// Create an unfulfilled future. init() {}
// Begin a coroutine by invoking `body`, and create a future representing // the eventual result of `body`'s completion. convenienceinit(_ body: () async -> T) { self.init() beginAsync { do { self.fulfill(await body()) } catch { self.fail(error) } } } }
To reiterate, it is well known that this specific implementation has performance and API weaknesses, the point is merely to sketch how an abstraction like this could be built on top of async/await.
Futures allow parallel execution, by moving await from the call to the result when it is needed, and wrapping the parallel calls in individual Future objects:
// ... other stuff can go here to cover load latency...
let imageTmp = await decodeImage(dataResource.get(), imageResource.get()) let imageResult = await dewarpAndCleanupImage(imageTmp) return imageResult }
In the above example, the first two operations will start one after another, and the unevaluated computations are wrapped into a Future value. This allows all of them to happen concurrently (in a way that need not be defined by the language or by the Future implementation), and the function will wait for completion of them before decoding the image. Note that await does not block flow of execution: if the value is not yet ready, execution of the current async function is suspended, and control flow passes to something higher up in the stack.
Other coordination abstractions such as Communicating Sequential Process channels or Concurrent ML events can also be developed as libraries for coordinating coroutines; their implementation is left as an exercise for the reader.
Conversion of imported Objective-C APIs
Full details are beyond the scope of this proposal, but it is important to enhance the importer to project Objective-C completion-handler based APIs into async forms. This is a transformation comparable to how NSError** functions are imported as throws functions. Having the importer do this means that many Cocoa APIs will be modernized en masse.
There are multiple possible designs for this with different tradeoffs. The maximally source compatible way to do this is to import completion handler-based APIs in two forms: both the completion handler and the async form. For example, given:
There are many details that should be defined as part of this importing process - for example:
What are the exact rules for the transformation?
Are multiple result functions common enough to handle automatically?
Would it be better to just import completion handler functions only as async in Swift 5 mode, forcing migration?
What should happen with the non-Void-returning completion handler functions (e.g. in URLSession)?
Should Void-returning methods that are commonly used to trigger asynchronous operations in response to events, such as IBAction methods, be imported as async -> Void?
Without substantial ObjC importer work, making a clean break and forcing migration in Swift 5 mode would be the most practical way to preserve overridability, but would create a lot of churn in 4-to-5 migration. Alternatively, it may be acceptable to present the async versions as final wrappers over the underlying callback-based interfaces; this would subclassers to work with the callback-based interface, but there are generally fewer subclassers than callers.
Interaction with existing features
This proposal dovetails naturally with existing language features in Swift, here are a few examples:
Error handling
Error handling syntax introduced in Swift 2 composes naturally with this asynchronous model.
1 2 3 4 5
// Could throw or be interrupted: funcprocessImageData() async throws -> Image
// Semantically similar to: funcprocessImageData(completionHandler: (result: Image?, error: Error?) -> Void)
Our example thus becomes (compare with the example processImageData2):
funcprocessImageData2() async throws -> Image { let dataResource = try await loadWebResource("dataprofile.txt") let imageResource = try await loadWebResource("imagedata.dat") let imageTmp = try await decodeImage(dataResource, imageResource) let imageResult = try await dewarpAndCleanupImage(imageTmp) return imageResult }
Coroutines address one of the major shortcomings of the Swift 2 error model, that it did not interoperate well with callback-oriented asynchronous APIs and required clumsy boilerplate to propagate errors across callback boundaries.
Closure type inference
Because the await keyword is used at all points where execution may be suspended, it is simple for the compiler to determine whether a closure is async or not: it is if the body includes an await. This works exactly the same way that the presence of try in a closure causes it to be inferred as a throwing closure. You can also explicitly mark a closure as async using the standard form of:
1
let myClosure = { () async -> () in ... }
defer and abandonment
Coroutines can be suspended, and while suspended, there is the potential for a coroutine’s execution to be abandoned if all references to its continuation closure(s) are released without being executed:
1 2 3 4 5
/// Shut down the current coroutine and give its memory back to the /// shareholders. funcabandon() async -> Never { await suspendAsync { _ = $0 } }
It is to be expected that, upon abandonment, any references captured in wait by the continuation should be released, as with any closure. However, there may be other cleanup that must be guaranteed to occur. defer serves the general role of “guaranteed cleanup” in synchronous code, and it would be a natural extension to add the guarantee that defer-ed statements also execute as part of cleaning up an abandoned coroutine:
funcprocessImageData() async throws -> Image { startProgressBar() defer { // This will be called when error is thrown, when all operations // complete and a result is returned, or when the coroutine is // abandoned. We don't want to leave the progress bar animating if // work has stopped. stopProgressBar() }
let dataResource = try await loadWebResource("dataprofile.txt") let imageResource = try await loadWebResource("imagedata.dat") do { let imageTmp = try await decodeImage(dataResource, imageResource) } catch_asCorruptedImage { // Give up hope now. await abandon() } returntry await dewarpAndCleanupImage(imageTmp) }
This fills in another gap in the expressivity of callback-based APIs, where it is difficult to express cleanup code that must execute at some point regardless of whether the callback closure is really called. However, abandonment should not be taken as a fully-baked “cancellation” feature; if cancellation is important, it should continue to be implemented by the programmer where needed, and there are many standard patterns that can be applied. Particularly when coupled with error handling, common cancellation patterns become very elegant:
Internally, imageProcessor may use NSOperation or a custom cancelled flag. The intent of this section is to give a single example of how to approach this, not to define a normative or all-encompassing approach that should be used in all cases.
Completion handlers with multiple return values
Completion handler APIs may have multiple result arguments (not counting an error argument). These are naturally represented by tuple results in async functions:
// After funcprocessImageHalves() async throws -> (Image, Image)
Source Compatibility
This is a generally additive feature, but it does take async and await as keywords, so it will break code that uses them as identifiers. This is expected to have very minor impact: the most pervasive use of async as an identifier occurs in code that works with dispatch queues, but fortunately keywords are allowed as qualified member names, so code like this doesn’t need any change:
1
myQueue.async { ... }
That said, there could be obscure cases that break. One example that occurs in the Swift testsuite is of the form:
This can be addressed by changing the code to use self.async or backticks. The compiler should be able to detect a large number of these cases and produce a fixit.
Effect on ABI stability
This proposal does not change the ABI of any existing language features, but does introduce a new concept that adds to the ABI surface area, including a new mangling and calling convention.
Alternate Syntax Options
Here are a couple of syntax level changes to the proposal that are worth discussing, these don’t fundamentally change the shape of the proposal.
Spelling of async keyword
Instead of spelling the function type modifier as async, it could be spelled as yields, since the functionality really is about coroutines, not about asynchrony by itself. The recommendation to use async/await biases towards making sure that the most common use case (asynchrony) uses industry standard terms. The other coroutine use cases would be much less common, at least according to the unscientific opinion of the proposal authors.
To give an idea of what this could look like, here’s the example from above resyntaxed:
funcprocessImageData1() yields -> Image { let dataResource = yield loadWebResource("dataprofile.txt") let imageResource = yield loadWebResource("imagedata.dat") let imageTmp = yield decodeImage(dataResource, imageResource) let imageResult = yield dewarpAndCleanupImage(imageTmp) return imageResult }
Make async be a subtype of throws instead of orthogonal to it
It would be a great simplification of the language model to make the async modifier on a function imply that the function is throwing, instead of making them orthogonal modifiers. From an intuitive perspective, this makes sense because many of the sorts of operations that are asynchronous (e.g. loading a resource, talking to the network, etc) can also fail. There is also precedent from many other systems that use async/await for this; for example, .NET Tasks and Javascript promises both combine error handling with async sequencing. One could argue that that’s because .NET and Javascript’s established runtimes both feature pervasive implicit exceptions; however, popular async frameworks for the Rust programming language, such as tokio.rs, have also chosen to incorporate error handling directly into their Future constructs, because doing so was found to be more practical and ergonomic than trying to compose theoretically-orthogonal Future<T> and Result<T> constructs.
If we made async a subtype of throws, then instead of four kinds of function type, we’d only have three:
1 2 3
(Int) -> Int// Normal function (Int) throws -> Int// Throwing function (Int) async -> Int// Asynchronous function, can also throw
The try marker could also be dropped from try await, because all awaits would be known to throw. For user code, you would never need the ugly async throws modifier stack.
A downside to doing this is that Cocoa in practice does have a number of completion handler APIs that do not take error arguments, and not having the ability to express that would make the importer potentially lose type information. Many of these APIs express failure in more limited ways, such as passing nil into the completion closure, passing in a BOOL to indicate success, or communicating status via side properties of the coordinating object; auditing for and recognizing all of these idioms would complicate the importer and slow the SDK modernization process. Even then, Swift subclassers overriding the async forms of these APIs would be allowed by the language to throw errors even though the error cannot really be communicated across the underlying Objective-C interface.
Make async default to throws
The other way to factor the complexity is to make it so that async functions default to throwing, but still allow non-throwing async functions to be expressed with nonthrowing (or some other spelling). This provides this model:
1 2 3 4
(Int) -> Int// Normal function (Int) throws -> Int// Throwing function (Int) async -> Int// Asynchronous function, can also throw. (Int) async(nonthrowing) -> Int// Asynchronous function, doesn't throw.
This model provides a ton of advantages: it is arguably the right defaults for the vast majority of clients (reducing boilerplate and syntactic noise), provides the ability for the importer and experts to get what they want. The only downside of is that it is a less obvious design than presenting two orthogonal axes, but in the opinion of the proposal authors, this is probably the right set of tradeoffs.
Behavior of beginAsync and suspendAsync operations
For async code to be able to interact with synchronous code, we need at least two primitive operations: one to enter a suspendable context, and another to suspend the current context and yield control back to the outer context. Aside from the obvious naming bikeshed, there are some other design details to consider. As proposed, beginAsync and continuation closures return Void to the calling context, but it may be desirable instead to have them return a value indicating whether the return was because of suspension or completion of the async task, e.g.:
1 2 3 4 5
/// Begin execution of `body`. Return `true` if it completes, or `false` if it /// suspends. funcbeginAsync(_ body: () async -> ()) -> Bool /// Suspend execution of the current coroutine, passing the current continuation/// into `body` and then returning `false` to the controlling context funcsuspendAsync<T>(_ body: (_ resume: (T) -> Bool) -> Void) async -> T
Instead of representing the continuation as a plain function value passed into the suspendAsync primitive, a specialized Continuation<T> type could be devised. Continuations are one-shot, and a nominal continuation type could statically enforce this by being a move-only type consumed by the resume operation. The continuation could also be returned by beginAsync or resuming a continuation instead of being passed into suspendAsync, which would put the responsibility for scheduling the continuation into the code that starts the coroutine instead of in the code that causes the suspension. There are tradeoffs to either approach.
Alternatives Considered
Include Future or other coordination abstractions in this proposal
This proposal does not formally propose a Future type, or any other coordination abstractions. There are many rational designs for futures, and a lot of experience working with them. On the other hand, there are also completely different coordination primitives that can be used with this coroutine design, and incorporating them into this proposal only makes it larger.
Furthermore, the shape and functionality of a future may also be affected by Swift’s planned evolution. A Future type designed for Swift today would need to be a class, and therefore need to guard against potentially multithreaded access, races to fulfill or attempts to fulfill multiple times, and potentially unbounded queueing of awaiting coroutines on the shared future; however, the introduction of ownership and move-only types would allow us to express futures as a more efficient move-only type requiring exclusive ownership to be forwarded from the fulfilling task to the receiving task, avoiding the threading and queueing problems of a class-based approach, as seen in Rust’s tokio.rs framework. tokio.rs and the C++ coroutine TR also both take the approach of making futures/continuations into templated/generic traits instead of a single concrete implementation, so that the compiler can deeply specialize and optimize state machines for composed async operations. tokio.rs and the C++ coroutine TR also both take the approach of making futures/continuations into templated/generic traits instead of a single concrete implementation, so that the compiler can deeply specialize and optimize state machines for composed async operations. Whether that is a good design for Swift as well needs further exploration.
Have async calls always return a Future
The most commonly cited alternative design is to follow the model of (e.g.) C#, where calls to async functions return a future (aka Task in C#), instead of futures being a library feature separable from the core language. Going this direction adds async/await to the language instead of adding a more general coroutine feature.
Despite this model being widely know, we believe that the proposed design is superior for a number of reasons:
Coroutines are generally useful language features beyond the domain of async/await. For example, building async/await into the compiler would require building generators in as well.
The proposed design eliminates the problem of calling an API (without knowing it is async) and getting a Future<T> back instead of the expected T result type. C# addresses this by suggesting that all async methods have their name be suffixed with Async, which is suboptimal.
By encoding async as a first-class part of function types, closure literals can also be transparently async by contextual type inference. In the future, mechanisms like rethrows can be extended to allow polymorphism over asynchrony for higher-level operations like map to work as expected without creating intermediate collections of Future<T>, although this proposal does not propose any such abstraction mechanisms in the short term.
The C# model for await is a unary prefix keyword, which does not compose well in the face of chaining. Wherein C# you may have to write something like x = await (await foo()).bar(), with the proposed design you can simply write x = await foo().bar() for the same reasons that you don’t have to write try on every single call in a chain that can throw.
It is useful to be able to design and discuss futures as an independent standard library feature without tying the entire success or failure of coroutines as a language proposal to Future‘s existence.
There are multiple different interesting abstractions besides futures to consider. By putting the details of them in the standard library, other people can define and use their own abstractions where it makes sense.
Requiring a future object to be instantiated at every await point adds overhead. Since a major use case for this feature is to adapt existing Cocoa APIs, which already use callbacks, queues, target-action, or other mechanisms to coordinate the scheduling of the continuation of an async task, introducing a future into the mix would be an additional unnecessary middleman incurring overhead when wrapping these APIs, when in most cases there is already a direct consumer for the continuation point.
A design that directly surfaces a monadic type like Future as the result of an async computation heavily implies a compiler-driven coroutine transform, whereas this design is more implementation-agnostic. Compiler-transformed coroutines are a great compromise for integrating lightweight tasks into an existing runtime model that’s already heavily callstack-dependent, or one aims to maintain efficient interop with C or other languages that heavily constrain the implementation model, and Swift definitely has both. It is conceivable that, in the eventual future, a platform such as Swift-on-the-server could provide a pure- or predominantly-Swift ABI where enough code is pure Swift to make cheap relocatable stacks the norm and overhead on C interop acceptable, as has happened with the Go runtime. This could make async a no-op at runtime, and perhaps allow us to consider eliminating the annotation altogether. The semantic presence of a future object between every layer of an async process would be an obstacle to the long-term efficiency of such a platform.
The primary argument for adding async/await (and then generators) to the language as first-class language features is that they are the vastly most common use-case of coroutines. In the author’s opinion, the design as proposed gives something that works better than the C# model in practice, while also providing a more useful/general language model.
Have a generalized “do notation” for monadic types
Another approach to avoiding the one-true-future-type problem of C# could be to have a general language feature for chaining continuations through a monadic interface. Although this provides a more general language feature, it still has many of the shortcomings discussed above; it would still perform only a shallow transform of the current function body and introduce a temporary value at every point the coroutine is “awaited”. Monads also compose poorly with each other, and require additional lifting and transformation logic to plumb through higher-order operations, which were some of the reasons we also chose not to base Swift’s error handling model on sugar over Result types. Note that the delimited continuation primitives offered in this proposal are general purpose and can in fact be used to represent monadic unwrapping operations for types like Optional or Result:
funcunwrap(_ value: T?) async -> T { iflet value = value { return value } suspendAsync { _in result = nil } }
beginAsync { body(unwrap) } }
Monads that represent repeated or nondeterministic operations would not be representable this way due to the one-shot constraint on continuations, but representing such computations as straight-line code in an imperative language with shared mutable state seems like a recipe for disaster to us.
Potential Future Directions
This proposal has been kept intentionally minimal, but there are many possible ways to expand this in the future. For example:
New Foundation, GCD, and Server APIs
Given the availability of convenient asynchrony in Swift, it would make sense to introduce new APIs to take advantage of it. Filesystem APIs are one example that would be great to see. The Swift on Server working group would also widely adopt these features. GCD could also provide new helpers for allowing () async -> Void coroutines to be enqueued, or for allowing a running coroutine to move its execution onto a different queue.
Documentation
As part of this introduction it makes sense to extend the Swift API design guidelines and other documentation to describe and encourage best practices in asynchronous API design.
rethrows could be generalized to support potentially async operations
The rethrows modifier exists in Swift to allow limited abstraction over function types by higher order functions. It would be possible to define a similar mechanism to allow abstraction over async operations as well. More generally, by modeling both throws and async as effects on function types, we can eventually provide common abstraction tools to abstract over both effects in protocols and generic code, simultaneously addressing the “can’t have a Sequence that throws“ and “can’t have a Sequence that’s async“ kinds of limitations in the language today.
Blocking calls
Affordances could be added to better call blocking APIs from async functions and to hard wait for an async function to complete. There are significant tradeoffs and wide open design space to explore here, and none of it is necessary for the base proposal.
Fix queue-hopping Objective-C completion handlers
One unfortunate reality of the existing Cocoa stack is that many asynchronous methods are unclear about which queue they run the completion handler on. In fact, one of the top hits for implementing completion handlers on Stack Overflow includes this Objective-C code:
// Some long running task you want on another thread
dispatch_async(dispatch_get_main_queue(), ^{ if (completion) { completion(); } }); }); }
Note that it runs the completion handler on the main queue, not on the queue which it was invoked on. This disparity causes numerous problems for Cocoa programmers, who would probably defensively write the @IBAction above like this (or else face a possible race condition):
1 2 3 4 5 6 7 8 9
@IBActionfuncbuttonDidClick(sender:AnyObject) { beginAsync { let image = await processImageData() // Do the update on the main thread/queue since it owns imageView. mainQ.async { imageView.image = image } } }
This can be fixed in the Objective-C importer, which is going to be making thunks for the completion-handler functions anyway: the thunk could check to see if the completion handler is being run on a different queue than the function was invoked on, and if so, enqueue the completion handler on the original queue.
Thanks
Thanks to @oleganza for the original draft which influenced this!
Hello, we are Team 4. My name is Patrick Wu, the team lead and a 2nd-Year Computer Science student at University College London. My interest mainly lies in low-level system design and networked systems. For this summer, I’m going to intern at a trading firm working on its infrastructural components. My teammate Yinrui(Felix) Hu, is also a second-year computer science student studying at UCL. He is mostly interested in artificial intelligence and cyber-security related fields. I am delighted to be working with Yinrui this year, and developed a brand new mobile application with many innovative approaches for UCL’s X5Learn research team, our industrial partner.
What have we been working on?
Online Education is no stranger to us, students, nowadays, as we have been utilising this extensively in day to day life. For instance, due to the recent COVID-19 outbreak, UCL students would all logon to Moodle to conduct remote learning through contents of formats including but not limited to videos, texts and audios. Apart from Moodle, there are such a great number of alternatives out there, e.g. Coursera, Khan Academy, LinkedIn Learning, MIT Open Courseware and many more. The trouble mainly lies which platform to choose instead of a lack of learning materials. As a student, we have spent way too long looking for a useful resource rather than learning itself. Therefore, X5GON and X5Learn as a Software-as-a-Service (SaaS), can solve this problem for you.
The main focus of X5GON development team is creating a solution that will help users/students find what they need not just in OER repositories, but across all open educational resources on the web. This solution will adapt to the user’s needs and learn how to make ongoing customised recommendations and suggestions through a truly interactive and impactful learning experience.
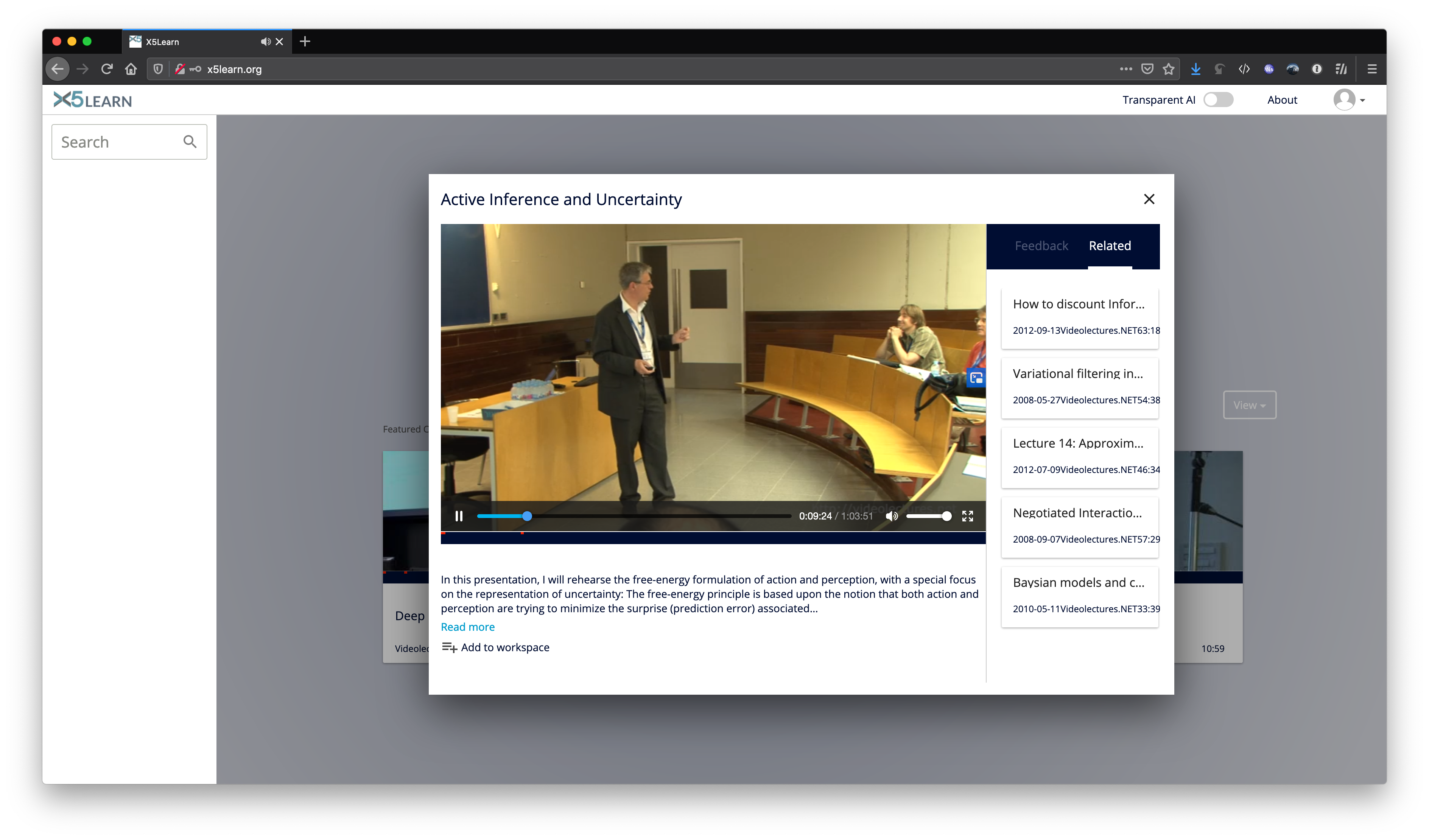
Figure 1. A demonstration of X5Learn’s website version.
Our goal, as a student team, is to develop a mobile application that utilises the X5Learn platform and provide an authentic and mobile-friendly user experience. With this mobile application, the X5Learn system would be able to attract more customers from the mobile platform and enable users to access their customised X5Learn learning contents at all times.
What are the technical challenges?
The critical challenge above all is to differentiate our application from other proprietary learning platforms. We continuously ask ourselves how to make the app more accessible and easy to navigate around for users. Given the fact there are many established applications out there, our team considered trying them out ourselves and conduct double-blind experiments on UI, app responsiveness and content relevancy experiments. We have learnt a lot in the process and greatly influenced our design of X5GON-Mobile afterwards.
Whilst we are testing out multiple applications under the eduroam network environment, there was one significant issue that emerged out of the dark. Some apps, under mediocre network environment, suffered from constant loss of network connection and plodding loading speed. Also, given the fact that the X5Learn usually takes 10 to 15 seconds to process videos and generate analytic reports, these together makes the app increasingly laggy and unusable at all under such circumstances. This issue of performance we noticed at an early stage influenced our application design and development process thereafter and is proven to be a significant differentiating factor for our application.
Last but not least, another essential technical challenge we faced was that the X5Learn was in ongoing development. Hence, many of the functionalities we aim to accomplish in our project are still in development or doesn’t exist as an API from the back-end. This caused us considerable trouble initially. However, we were able to overcome this difficulty eventually and made our application more adaptable to this type of situation, which would be beneficial for future expansion of the whole platform after our delivery of the project.
How did we solve them?
Figure 2. An overview of the technologies used in this project.
We tackled challenges above using advanced technology provided by Apple, the open-source community and algorithms written by ourselves.
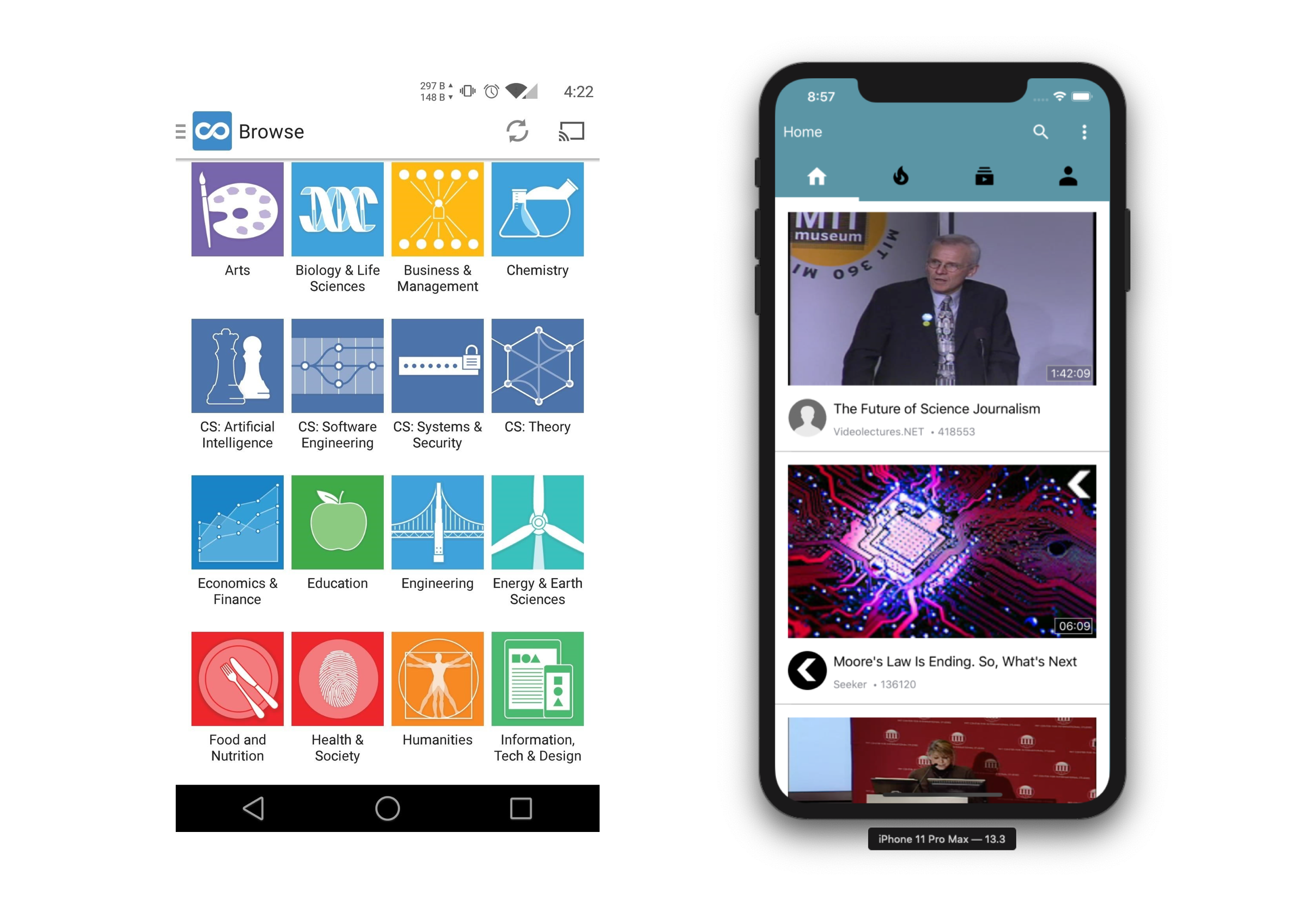
Figure 3. A comparison between traditional learning app and our approach.
From a design perspective, we took the information-feed approach rather than listing all courses available for the users find. As on most other platforms, users would have to search for what they want to learn, we actively push this information to the screen for users to choose from, similar to video sites but unlike a learning platform. Our design also utilises an innovative way of enabling users to read bullet-points or browse external supportive contents. Users can scroll to a sidebar whilst not stopping the video and start from there. They can also minimise the video to let it play as a floating window at the bottom of the screen. This design received great feedback from our clients and users at our testing stage.
Figure 4. A demonstration of our app’s performance on videos.
With regards to the performance of the application, we utilised extensive caching and predicting techniques to minimise the lag and increase the responsiveness. First of all, the choice of using Swift to develop a native iOS application provides us with a faster foundation compared to hybrid frameworks like React Native. More so, our aggressive pre-loading daemon utilised a HashMap storing technique and regularly fetches first 20-seconds of content whenever user finds the thumbnail on display. Although we did make a trade-off of having more background tasks, which is negligible, app users now receive a notably faster application and smoother learning experience.
As a project that has both the ongoing development of front-end and back-end at the same time, we found it challenging to adapt to the constant changing API as an external mobile application. Therefore, we then utilised SwiftSoup, an external parser for HTML, together with our own algorithm to analyse changing API endpoints on the fly and self-adapt the code. This still at an early stage and would require a constant change of code to actually make the new version work. However, this adaptive API layer has undoubtedly saved us a lot of time investigating broken APIs and migrating to new ones.
Some Final Thoughts
Having never developed an iOS application, we have learned a lot about Apple ‘s tool-chain and especially the Swift language. While developing this project, an issue among which also encouraged to make an actual contribution to the apple/swift language on its co-routine implementation. Our team find this year of cooperating with UCL’s X5Learn Team very enjoyable and worthwhile.
In computer programming, package principles are a way of organizing classes in larger systems to make them more organized and manageable. They aid in understanding which classes should go into which packages (package cohesion) and how these packages should relate with one another (package coupling). Package principles also includes software package metrics, which help to quantify the dependency structure, giving different and/or more precise insights into the overall structure of classes and packages.
An important counterpart of which is namespace in C++. CPPReference states that
Namespaces provide a method for preventing name conflicts in large projects.
Symbols declared inside a namespace block are placed in a named scope that prevents them from being mistaken for identically-named symbols in other scopes.
Multiple namespace blocks with the same name are allowed. All declarations within those blocks are declared in the named scope.
Discussion on functions in namespaces or classes
Putting an isolate function in a namespace could be rather a better decision than incorporating it in a class as a method, contradicting to what we have learnt from COMP0004. More specifically, whenever you can implement some functionality efficiently without having to access any private or protected code or data members, you should break it into a free function in the class’s namespace instead of leaving it as a member function. The reason is that by doing so, you keep the class’s interface as small as possible, and thereby reduce the amount of code that potentially needs to be changed if you change the private internals of the class, which is the point of Objective Oriented Programming (OOP) in the first place. Scott Meyers, author of Effective C++, goes into more detail here.
Unfortunately, separating out code that works on T from the class T itself just feels untidy to many programmers raised on the OOP mantra of “Bring code and data together”. But “bringing code and data together” doesn’t actually achieve anything material from a code maintenance or expressiveness point of view — all it gets you is a certain aesthetic appeal, so if you can get past that, you will benefit from the materially better design that comes from keeping class interfaces as small as possible.
If it takes a while to convince yourself that separate functions are actually the Right Thing, don’t feel bad — Meyers’s own first edition of Effective C++ made the same mistake. An example of the C++ Standard Library getting it wrong would be a function like find_first_of() in std::string, which can be implemented with full efficiency without having to know any of the internal details of a std::string — all such a function needs is access to the public functions size() and operator[]().
To end with Scott Meyers own paragraph,
It’s time to abandon the traditional, but inaccurate, ideas of what it means to be object-oriented. Are you a true encapsulation believer? If so, I know you’ll embrace non-friend non-member functions with the fervor they deserve.
This indicates that all outcomes from interval $(a, b)$ are equally likely.
Possible Usage: as a starting point in simulations, if we can generate a random number in $U(0, 1)$, we can arbitrarily expand the range to almost any other uniform distribution
Two continuous random variables $X$ and $Y$ are independant
Example
Given a unit circle marked with $0, 1, 2, 3$ at $\theta = 0, \frac{\pi}{2}, \pi, \frac{3\pi}{2}$ respectively. The circumference of the unit circle has value range from $0 \leq Y < 4$.
A pointer from the origin with length of $1$ is spun and is equally likely to stop anywhere on the circle. Let $Y$ be the value obtained from the circle.
$Y$ is a continuous random variable.
In the example above
Next
In the next post, we will be looking at continuous distributions, as similar to discrete distributions in previous posts here, part 1 and here, part 2.
Hi, I have decided to start a series to blog post to enrich my blog content and also, share several insights of myself when learning C++, especially modern C++ features.
I have made a list below on possible features I am looking at to write in this series.
More on OOP: Inheritance, Virtual Functions, Interfaces, Visibility
STLs
Macros and Lambdas
Namespaces
Threads, Concurrency features
Design Patterns: Singletons, Factories
Move semantics, Rvalue References, Forwarding References, auto keyword
Maps and Sets Splicing
Parallel Algorithms in C++17
This is the content list for the moment, and I believe this will keep me busy for a while. However, if there is something specific you want to see, please don’t hesitate to drop me an email at patrick.wu (at) linux.com .
Last time we talked about CSRF tokens. So what is CSRF?
Cross-Site Request Forgery
Well, Wikipedia has a brief explanation of how it works. In short,
Cross-site request forgery, also known as one-click attack or session riding and abbreviated as CSRF (sometimes pronounced sea-surf[1]) or XSRF, is a type of malicious exploit of a website where unauthorized commands are transmitted from a user that the web application trusts.
There are many ways to utilise CSRF on unprotected websites. However, this can be largely prevented by providing the user with a csrf_token only when they logging in on the valid website, and storing them in sessions.
Solution
My final solution to this problem, in the Swift code below, is to use a web request to get a csrf_token and then login with a valid user request.
staticfuncfetchCSRFToken() -> String { var csrfToken = "" let semaphore = DispatchSemaphore(value: 0) let task = URLSession.shared.dataTask(with: URL.init(string: newAdapter.generateLoginQueryURL())!) {(data, response, error) in defer { semaphore.signal() } guardlet data = data else { return } do { let divFields: Elements = trySwiftSoup.parse(String(decoding: data, as: UTF8.self)).body()!.select("div") let centreDiv = divFields.array()[1] let inputFields = try centreDiv.select("form").first()!.select("input") for inputField in inputFields { if inputField.id() == "csrf_token" { csrfToken = try inputField.val() } } } catch { print("error: cannot fetch csrf token") } } task.resume() semaphore.wait() if (csrfToken == "") { fatalError("error: cannot fetch csrf token") } else { return csrfToken } }
Afterwards, generate a POST request in JSON style (e.g. {email: "[email protected]", password:"pwd", csrf_token:"token"}) and post it to your designated flask-security login endpoint. You will get a response with your authentication token. From then on, use this authentication token for future requests.
What’s more?
Authentication tokens should have a valid lifetime and re-authenticate from time to time to ensure better security. We have yet to come up with a solution to modify flask-security‘s internal mechanisms to realise this feature.
Regarding the HTTP request, we are planning to adapt to Alamofire for more elegant network solutions.